고정 헤더 영역
상세 컨텐츠
본문
반응형
구글 GCP를 세팅하고 구글 GCP 가상환경에 Spark를 설치하자
▣ Google GCP 링크
https://cloud.google.com/?authuser=1&hl=ko
영상 통화, 이메일, 채팅, 문서 공동작업을 한곳에 통합할 수 있습니다.
cloud.google.com
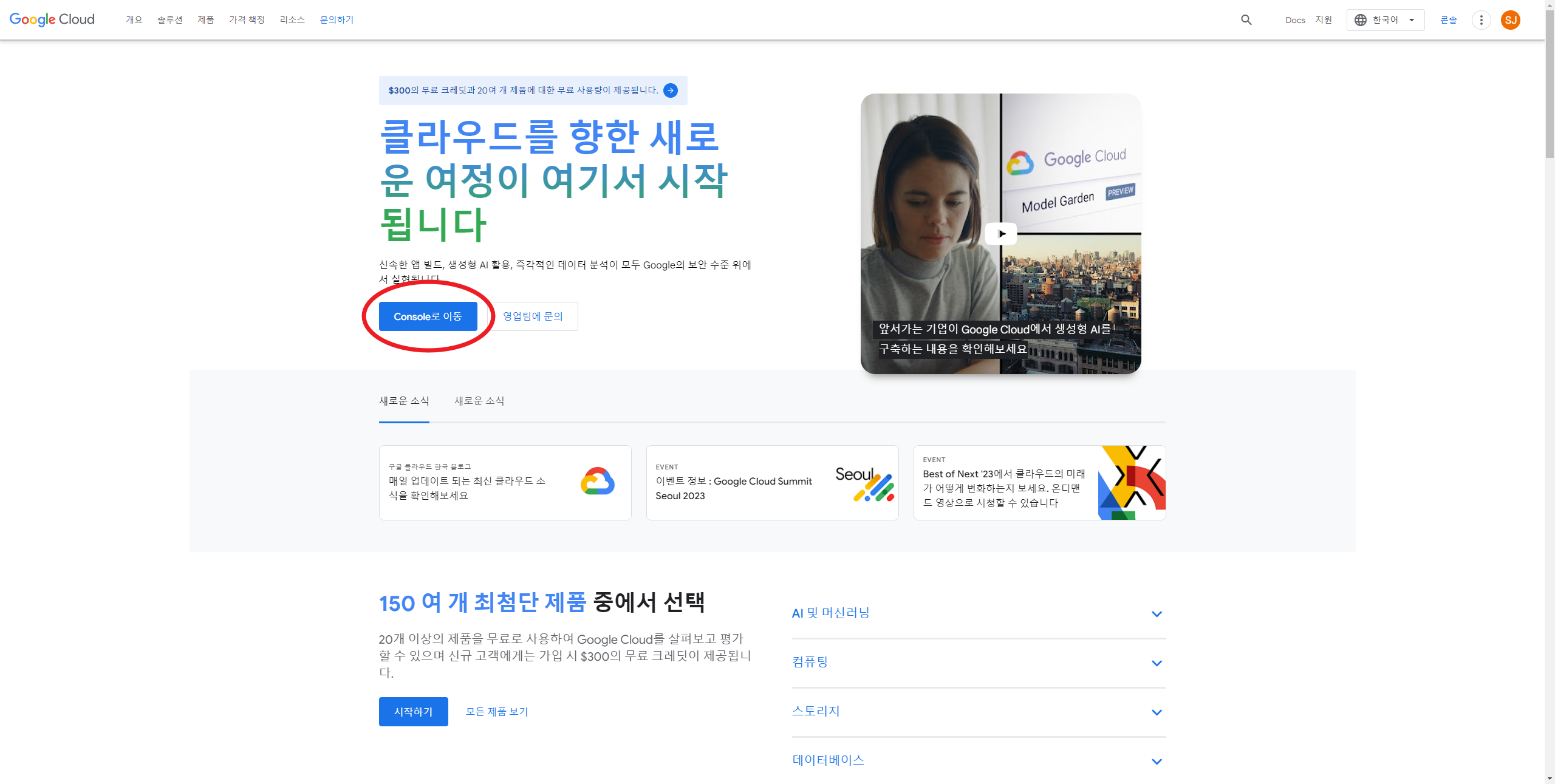
1. 먼저 구글 GCP로 접속하여 아래의 Console로 이동을 클릭한다.
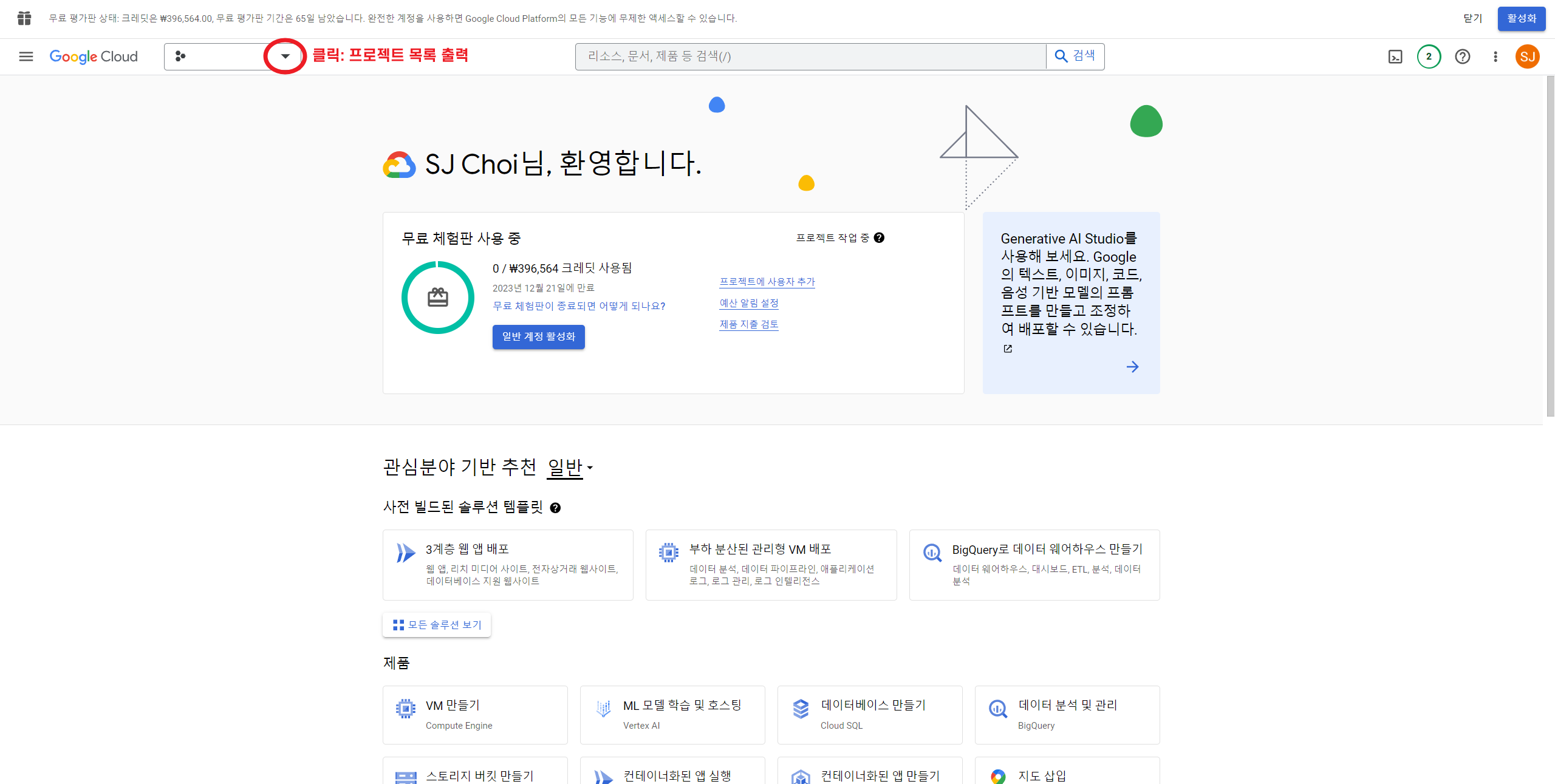
2. 좌측 상단의 프로젝트 목록을 클릭하여 프로젝트 목록을 띄운다.
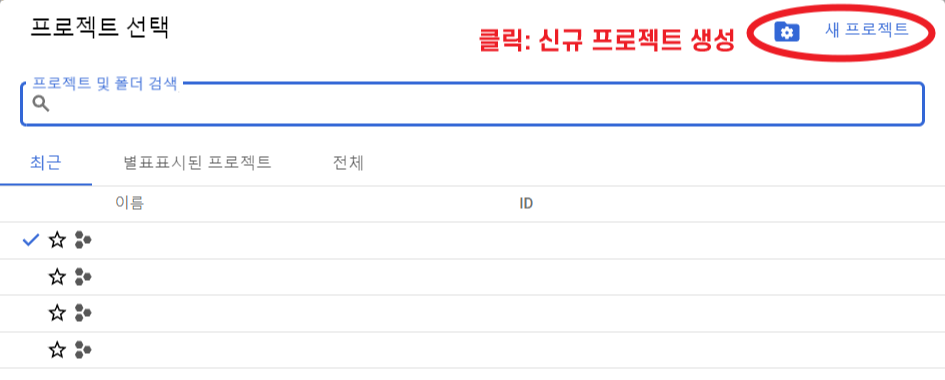
3. 우측 상단의 새 프로젝트를 클릭하여 신규 프로젝트를 생성해준다.
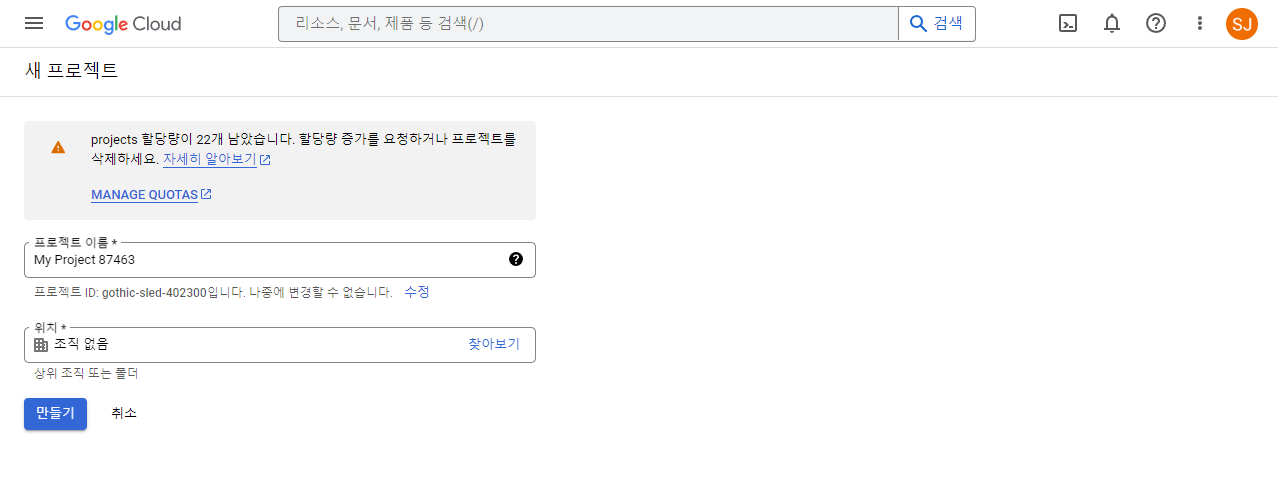
4.프로젝트명만 임의로 지정해주고 위치는 생략한 후 만들기를 클릭한다.
6. 상단 검색화면에서 Compute Engine API를 검색하기
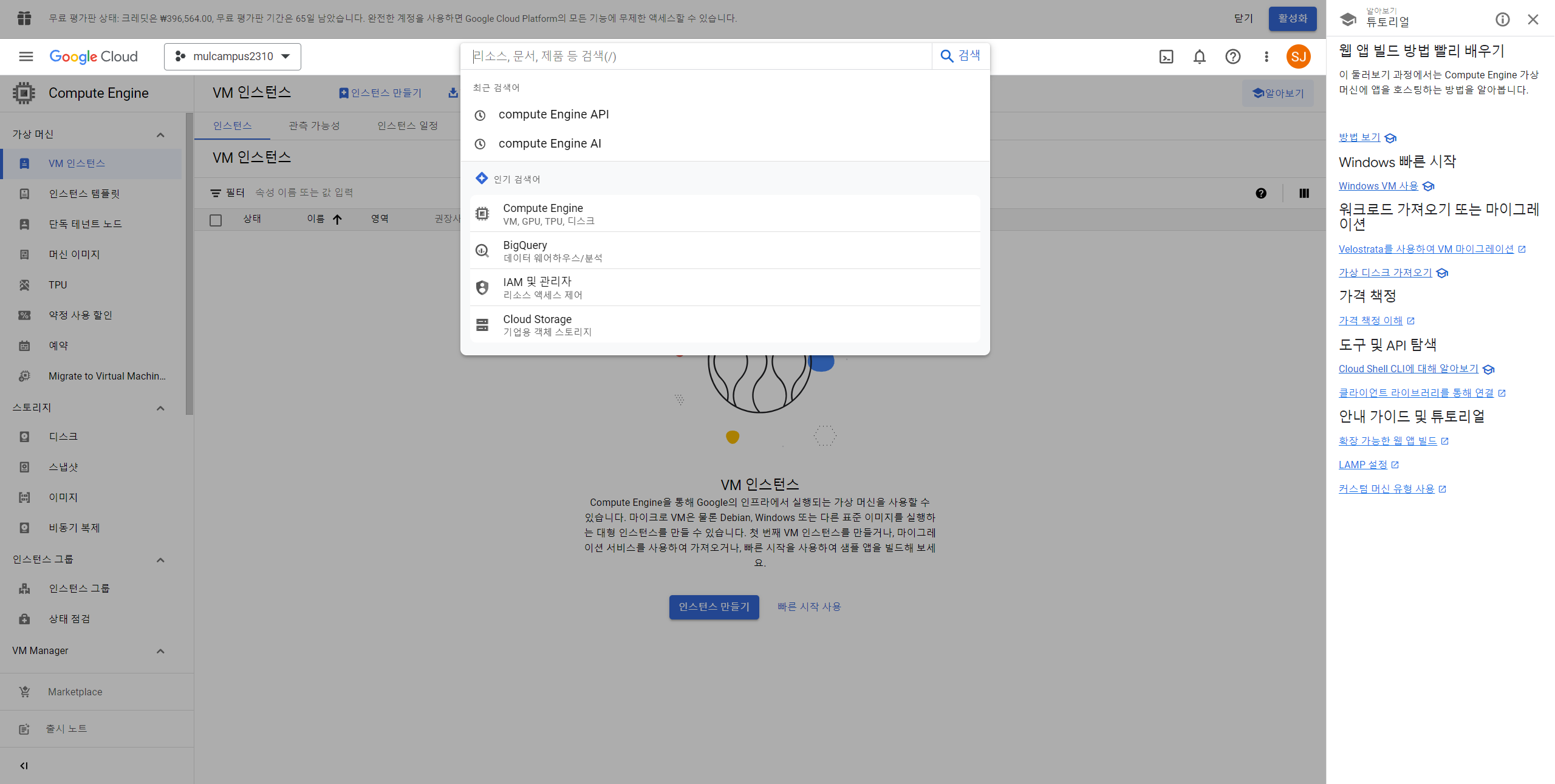
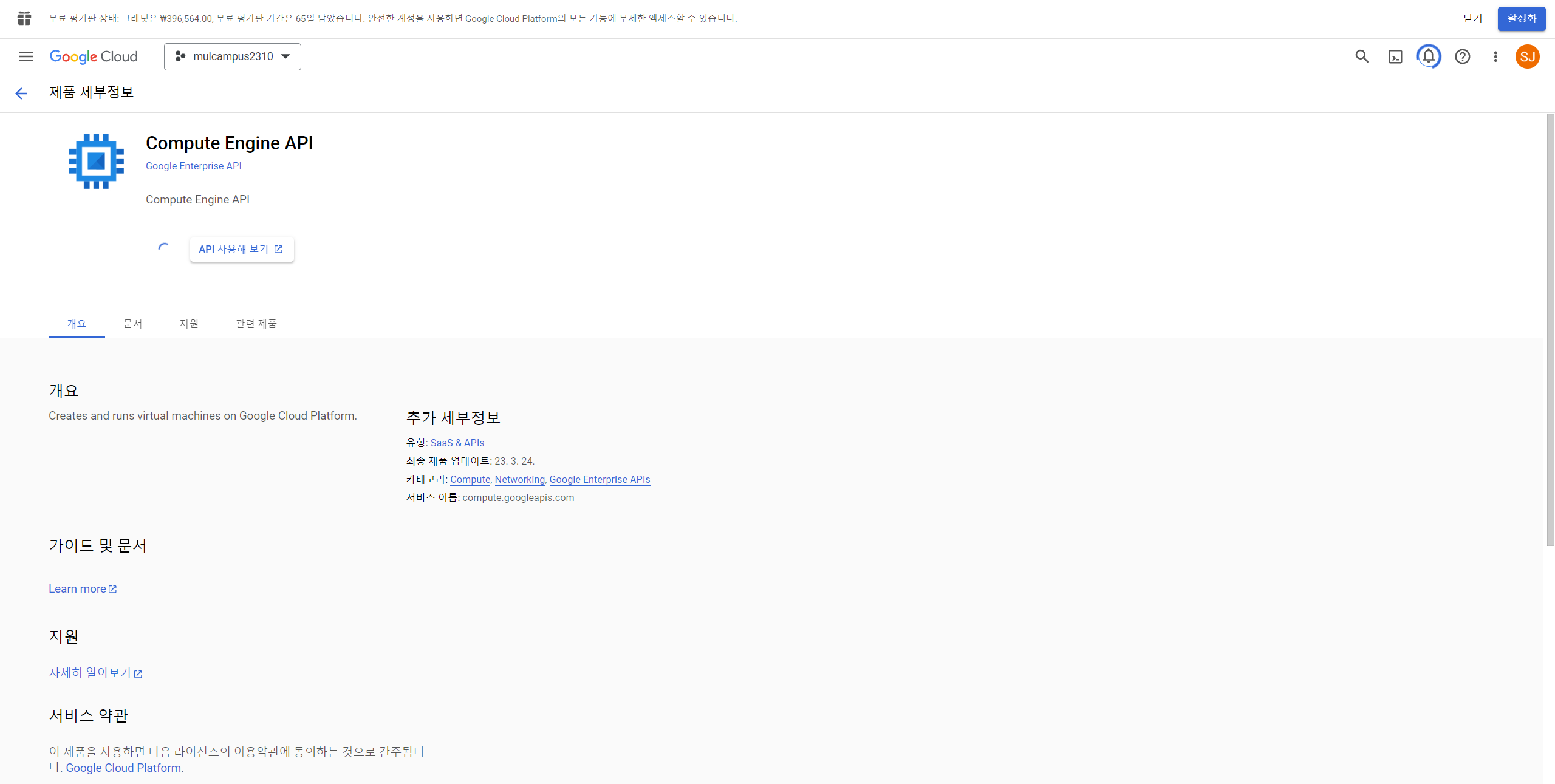
7. Compute Engine API 제품 세부정보에서 "사용" 클릭하기(현재 버퍼링 중인 모습)

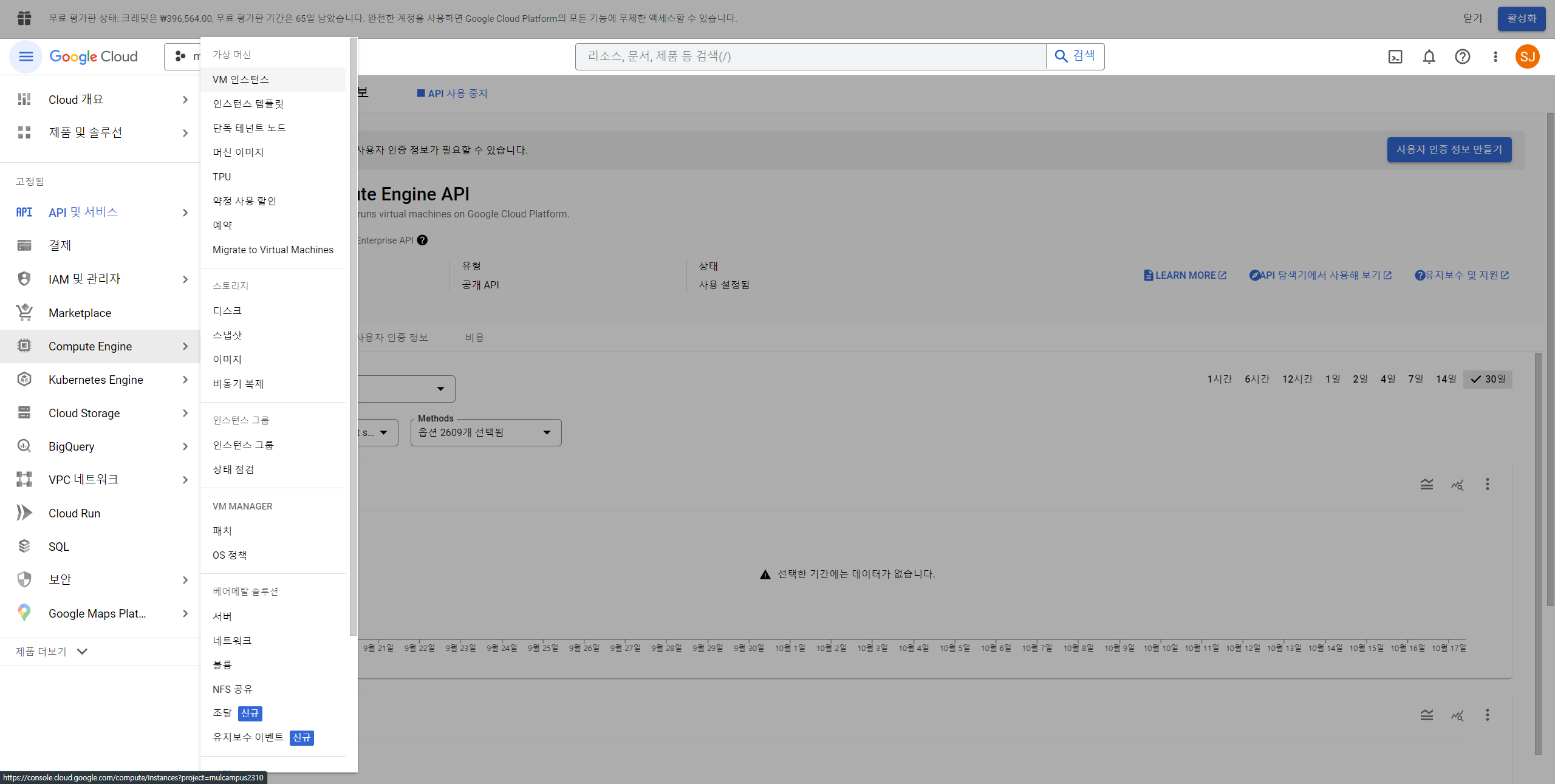
8. 삼단바 클릭 후 Compute Engine > VM 인스턴스 클릭
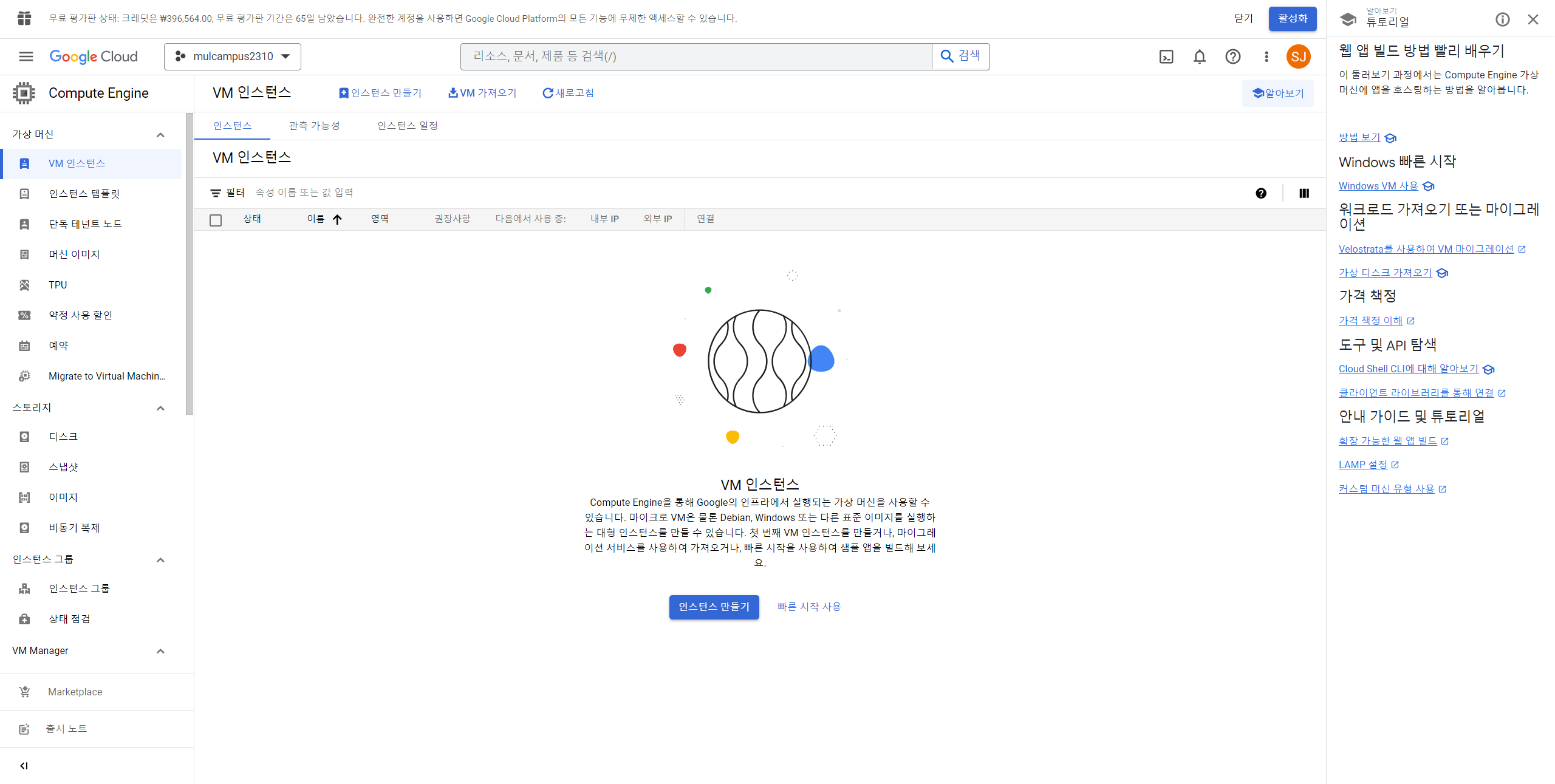
9. 화면 상단에서 "인스턴스 만들기" 클릭
10. 아래 사진과 같이 세팅 해준다.
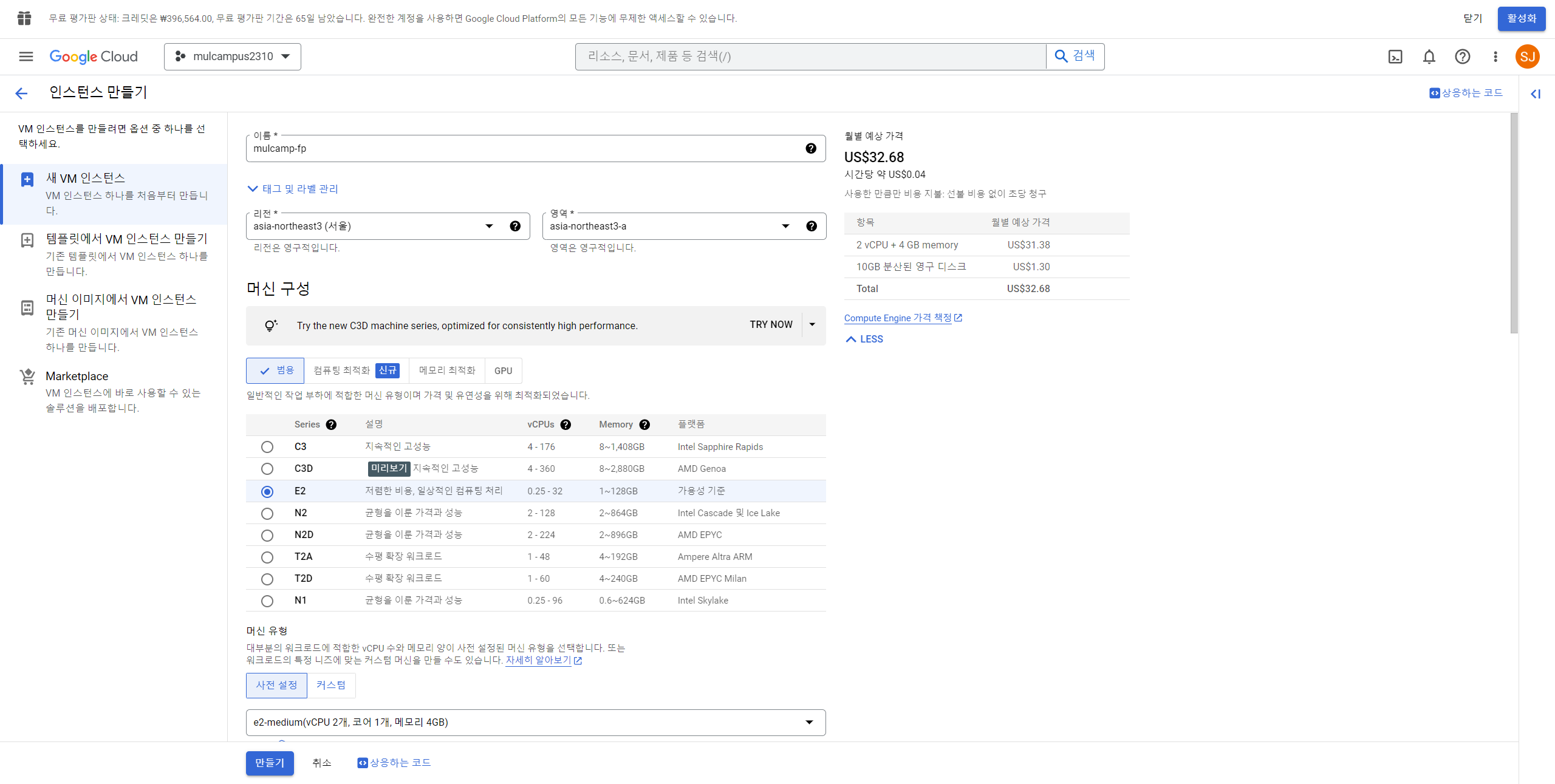
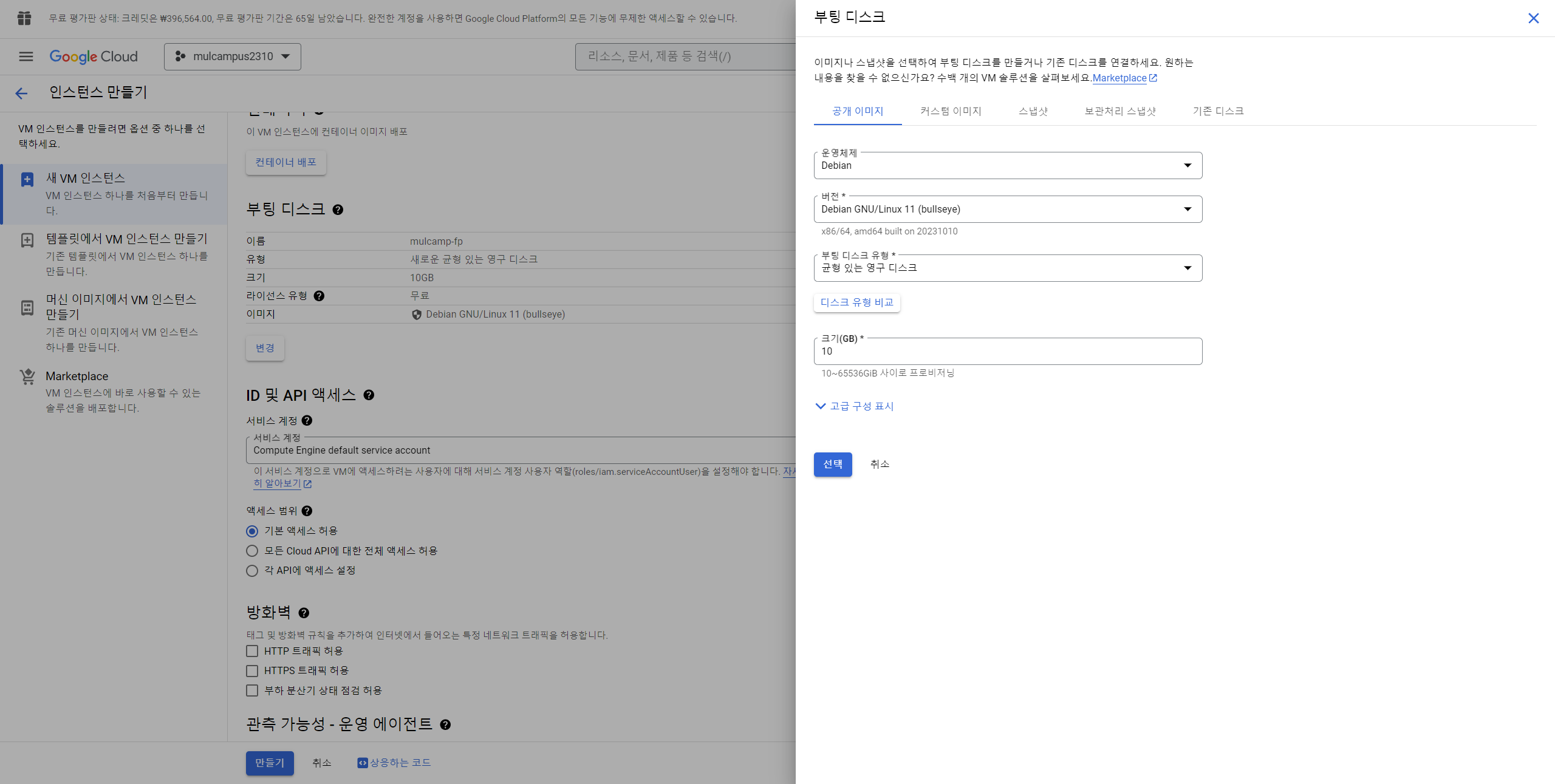
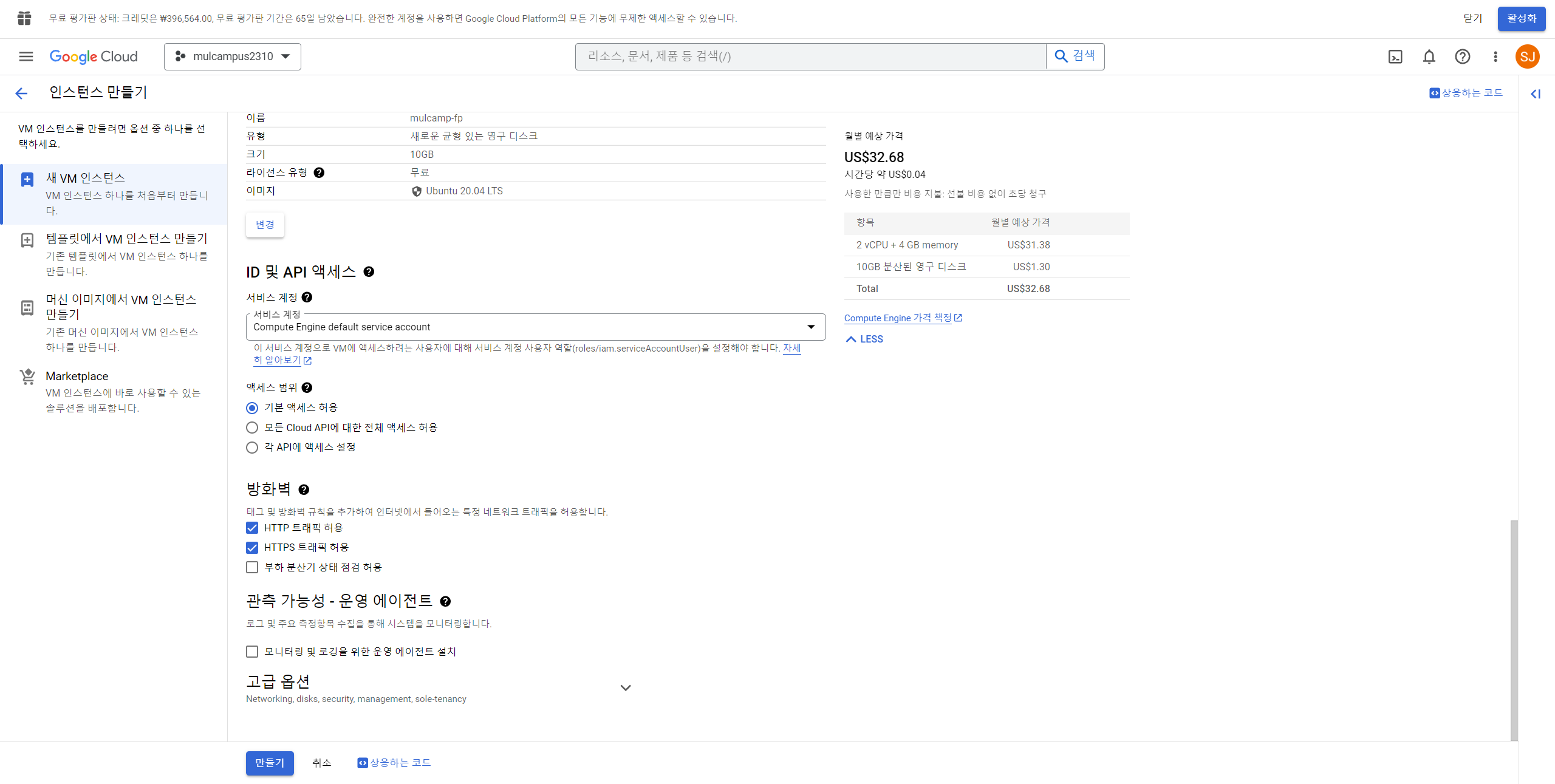
11. 10-1 부터 10-3 까지 진행 후 마무리되면 10-3 그림의 "만들기" 클릭
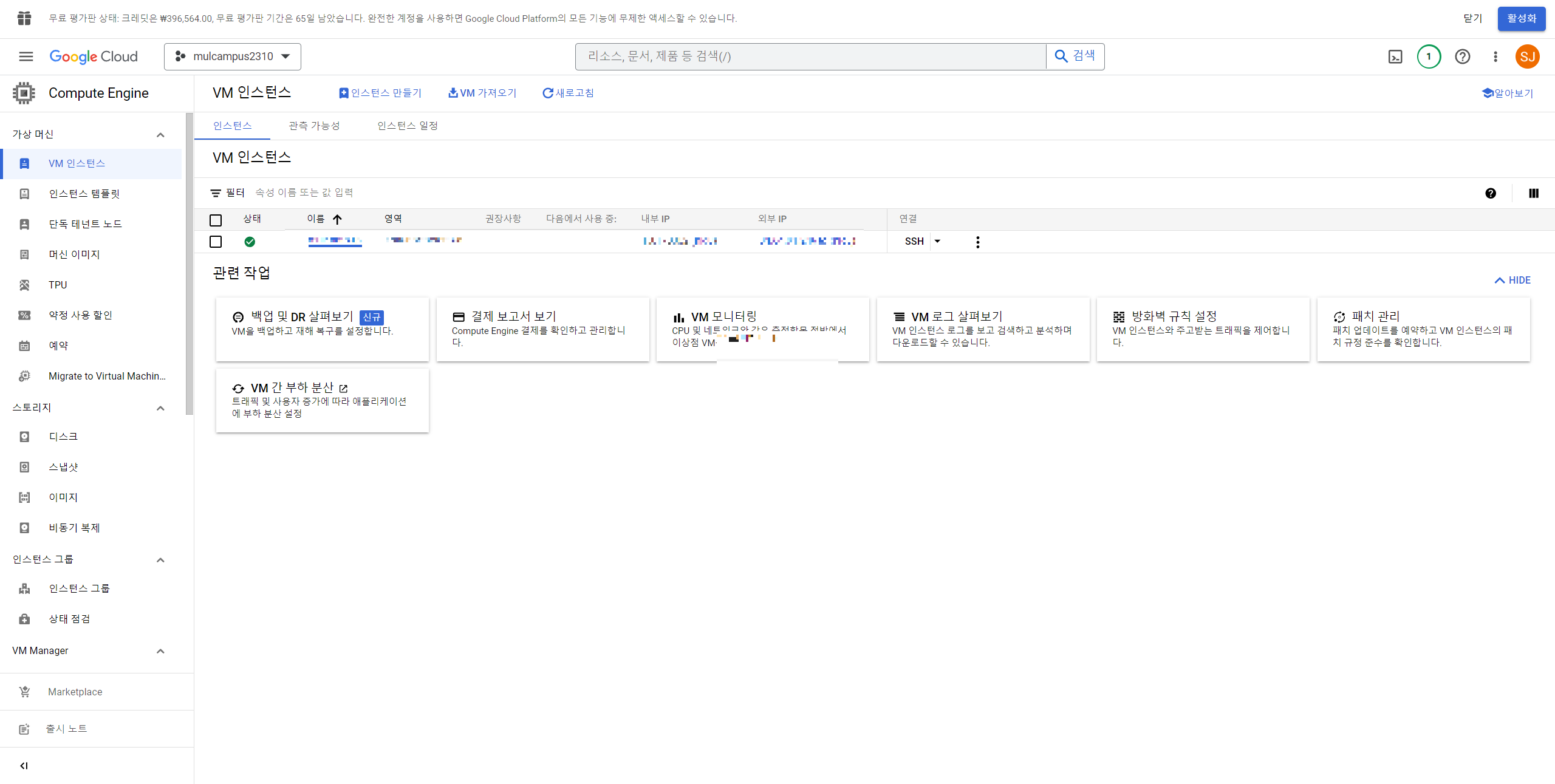
아래와 같이 만들어진 모습을 확인할 수 있다.
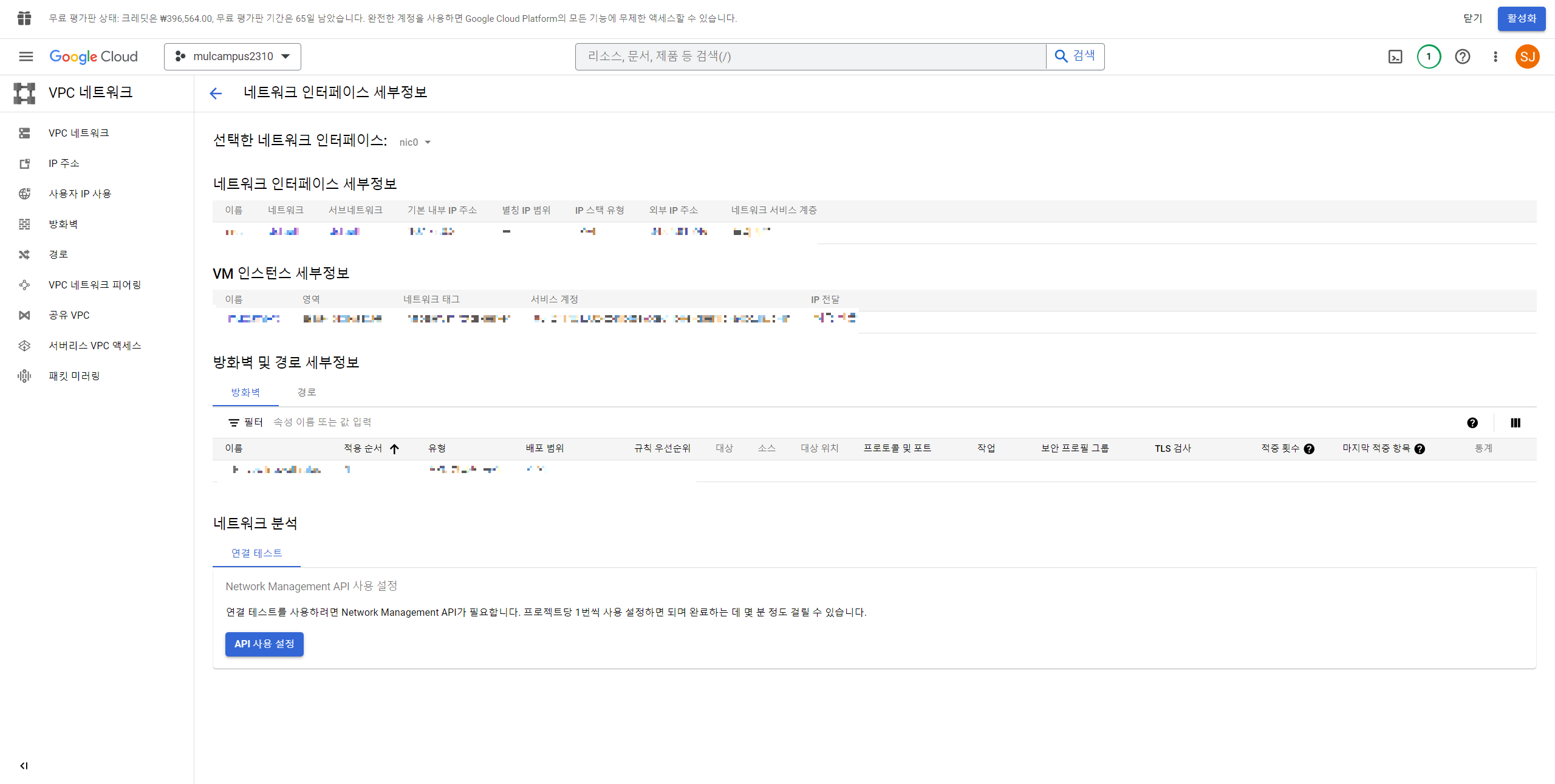
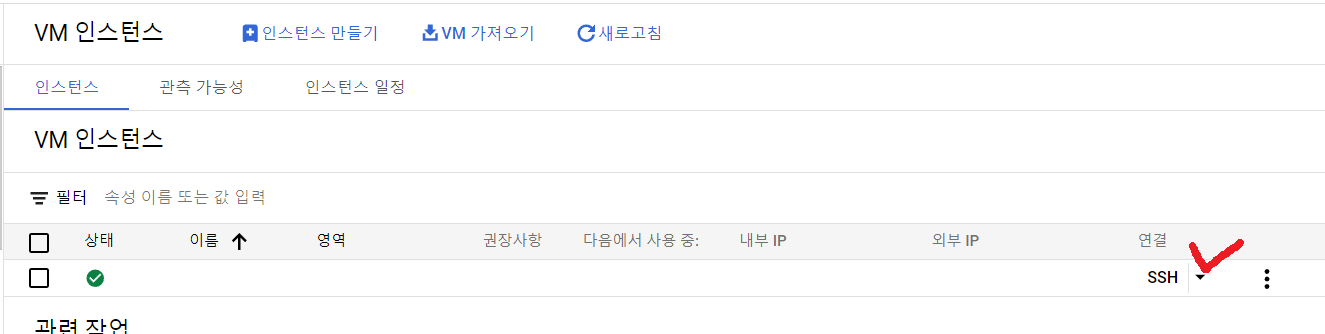
연결 컬럼에서 SSH 우측에 있는 ... 을 클릭하고 네트워크 세부정보 보기를 클릭한다.
12. 방화벽 클릭 -> 방화벽 정책 -> 방화벽 규칙 만들기(캡쳐 참고)
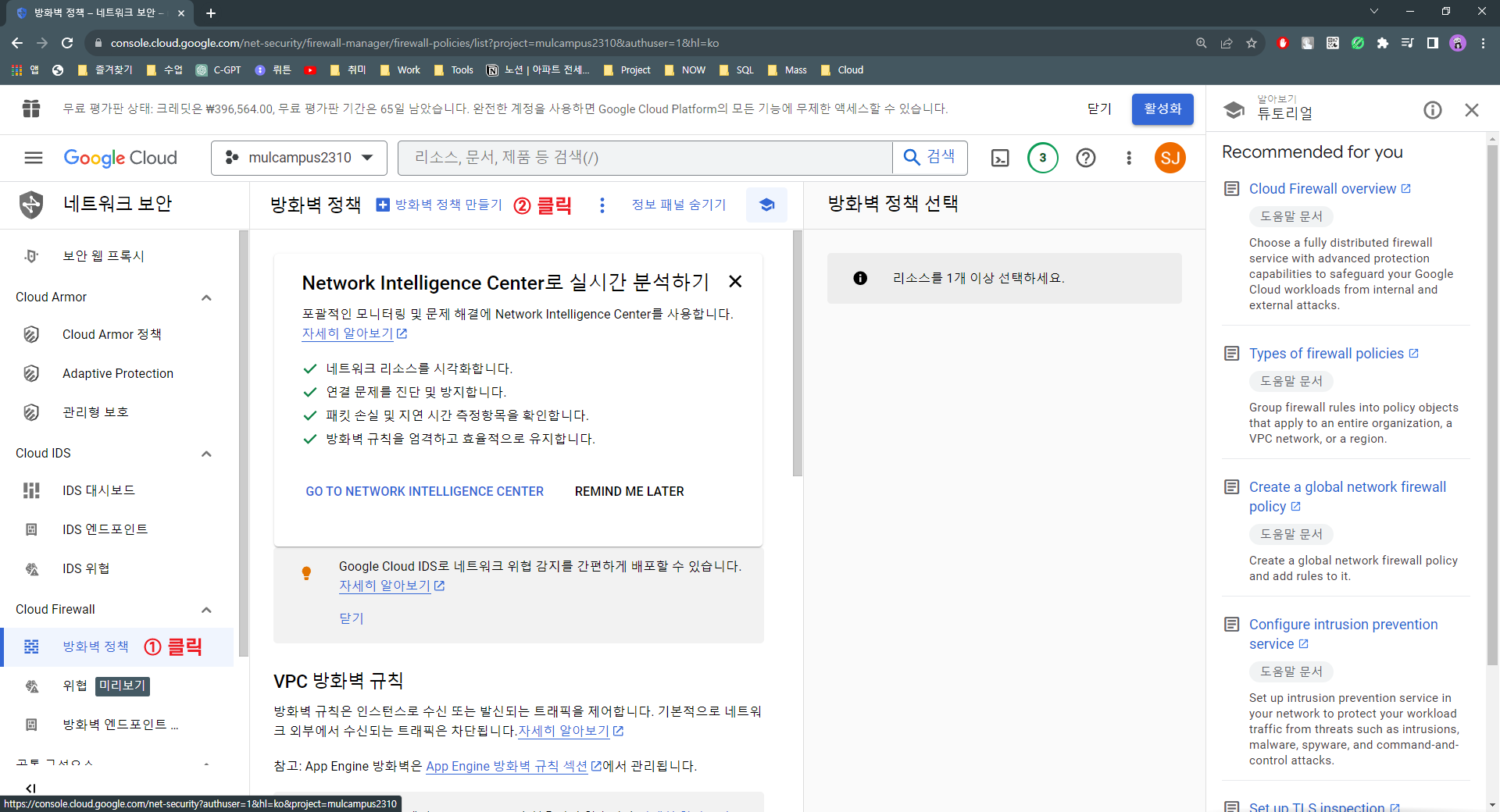
13. 방화벽 클릭 -> 방화벽 정책 -> 방화벽 규칙 만들기(캡쳐 참고)
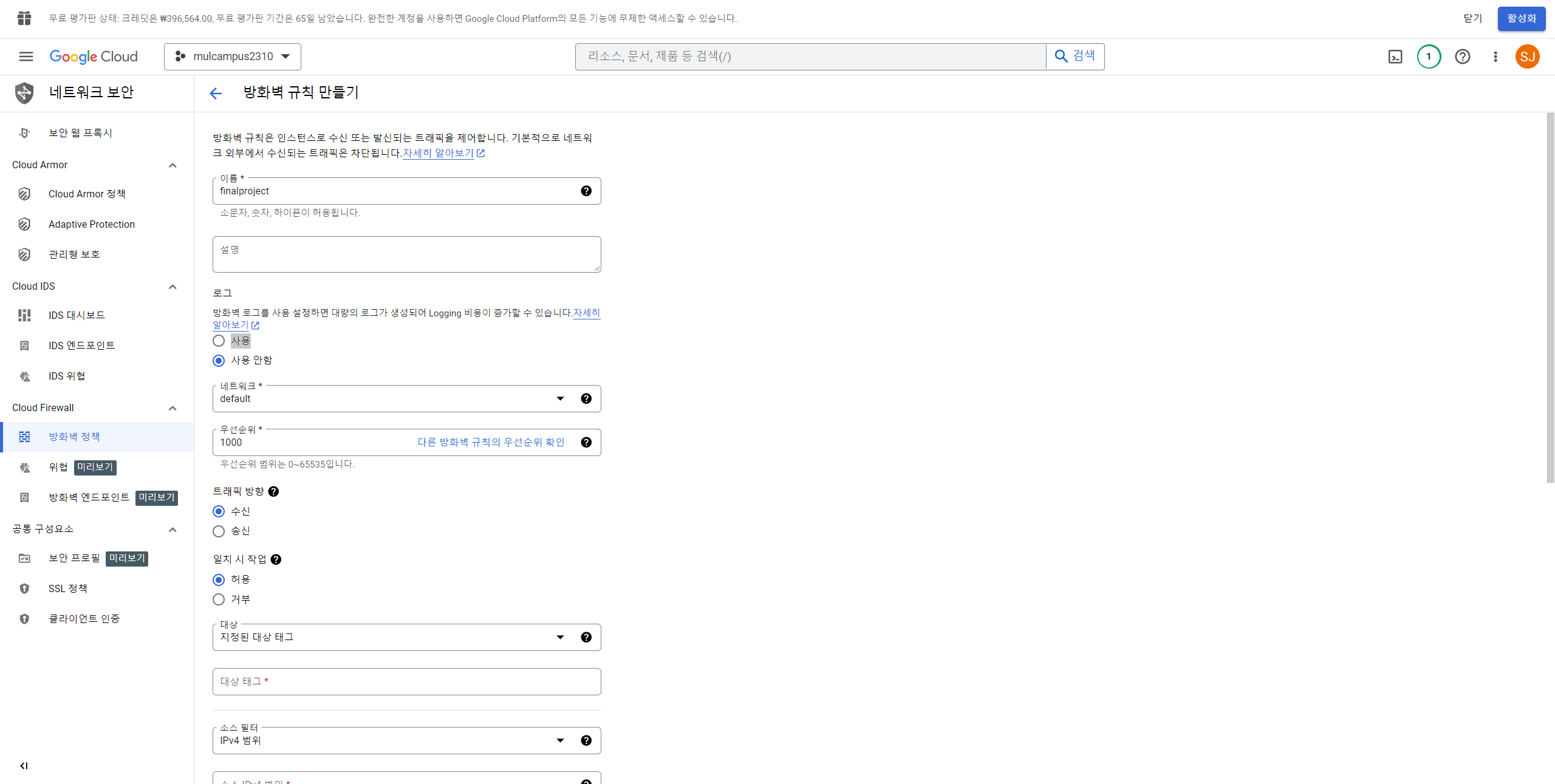
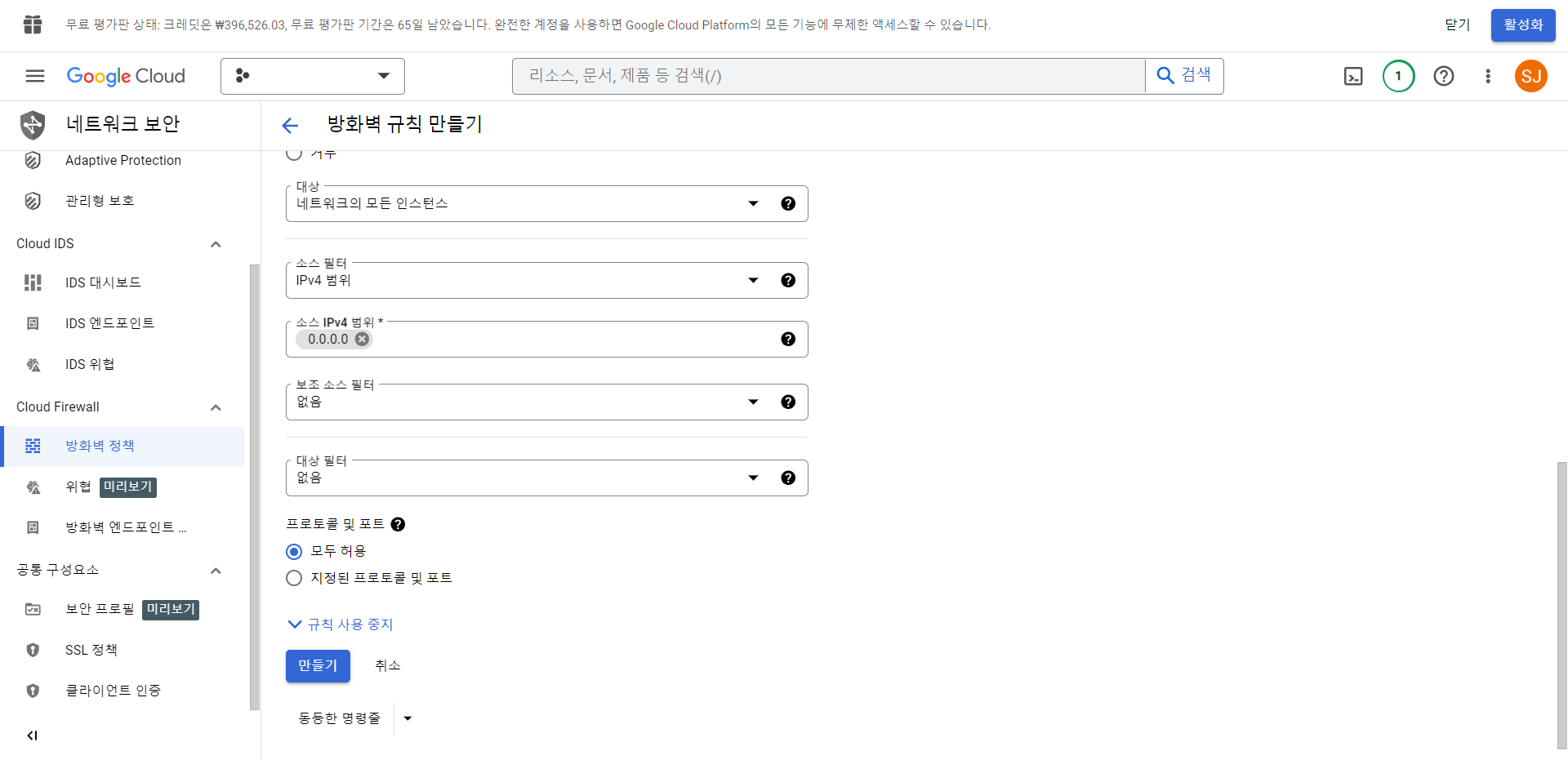
14. 다시 Compute Engine의 VM 인스턴스에 접속한다.
아래 사진과 같은 ▼ 를 클릭하여 브라우저 창에서 열기를 클릭 해준다.

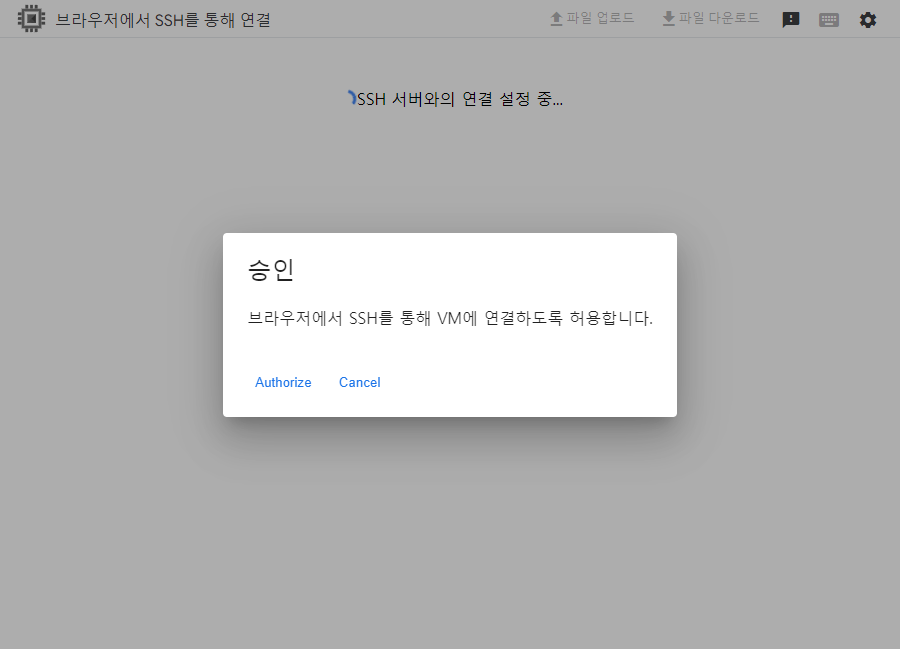
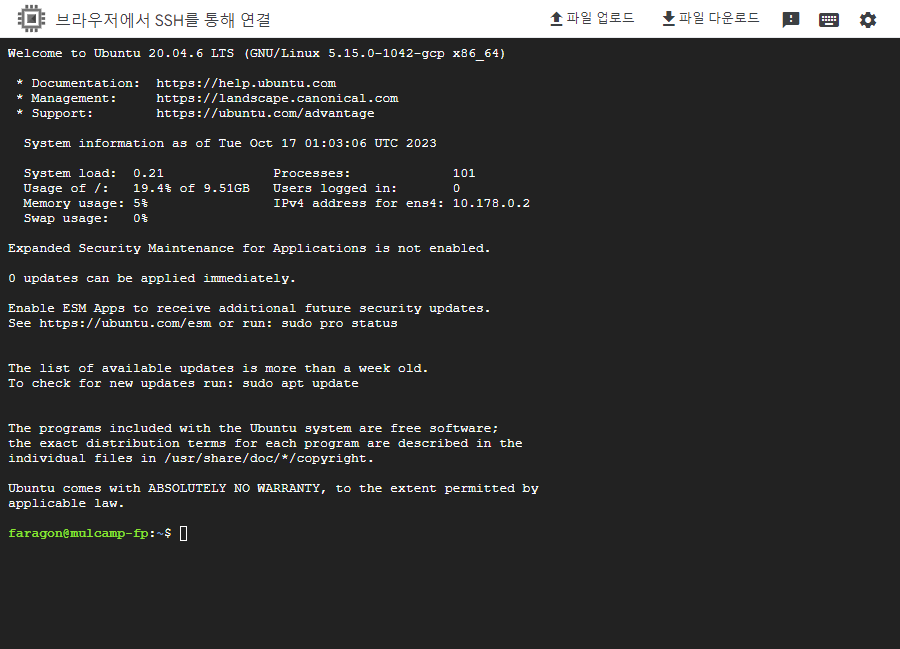
15. 아래와 같이 SSH 리눅스 우분투 환경의 터미널로 브라우저 접속이 된다.
당연히 승인은 "Autorize" 해주시면 됩니다.
16. 터미널 라이브러리 설치 및 환경변수설정 방법
사용된 명령어 정리하기
스파크 인스톨 사이트: https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
스파크 버전 아카이브: https://archive.apache.org/dist/spark/
Index of /dist/spark
archive.apache.org
# 기본 명령어
ls
pwd
cd ../../opt
# 미니콘다 설치 명령어
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
# 미니콘다 설치 완료 후 VM 인스턴스 정지 후 새로고침하고 재시작
# 브라우저 터미널 접속해준다.
# 자바설치 코드입력
sudo apt update
ls
cd ../../opt
sudo apt install openjdk-8-jdk -y
# vi 편집 및 환경변수 설정
ls
vi ~/.bashrc
# JAVA ENV SET
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=$JAVA_HOME/lib:$CLASS_PATH
i : insert모드 진입
esc : insert 모드 해제
: 누르고 wq! vi 편집기 저장하고 나가기
source ~/.bashrc : 환경변수 적용하기
위 작동법으로 vi편집 텍스트 맨 아래로 가서 수정한다.
# 스칼라 환경 변수 설정 코드 입력
sudo apt-get install scala -y
vi ~/.bashrc
맨 하단에가기
i
# SCALA ENV SET
export SCALA_HOME=/usr/bin/scala
export PATH=$SCALA_HOME/bin:$PATH
dd = 한줄 없애기
end = 현재 줄 끝으로 가기
# 러닝 스파크 설치 코드
sudo wget https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
sudo tar xvf spark-3.1.1-bin-hadoop2.7.tgz
sudo mkdir spark
sudo mv spark-3.1.1-bin-hadoop2.7/* /opt/spark/
cd spark
ls
cd ..
cd spark-3.1.1-bin-hadoop2.7/
cd ..
# Spark 환경 변수 세팅
cd $home
ls
>> 이름 확인
이름: faragon
# SPARK ENV SET
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/home/your_id/miniconda3/bin/python
# 해당 서버(가상환경)에 pyspark 설치
pip install pyspark==3.1.1
cd $HOME
pyspark
exit()
# 주피터 노트북 설치하기
conda install jupyter notebook
jupyter notebook --generate-config
# 주피터 환경설정 vi 편집기 들어가기
vi ~/.jupyter/jupyter_notebook_config.py
/.allow_root 주석 풀고 False를 True로 변경
/.ip = 주석 풀고 Localhost를 0.0.0.0으로 변경
17. 위의 설정이 끝난 후 터미널에서 jupyter notebook 을 입력하여 주피터 노트북을 실행해준다.
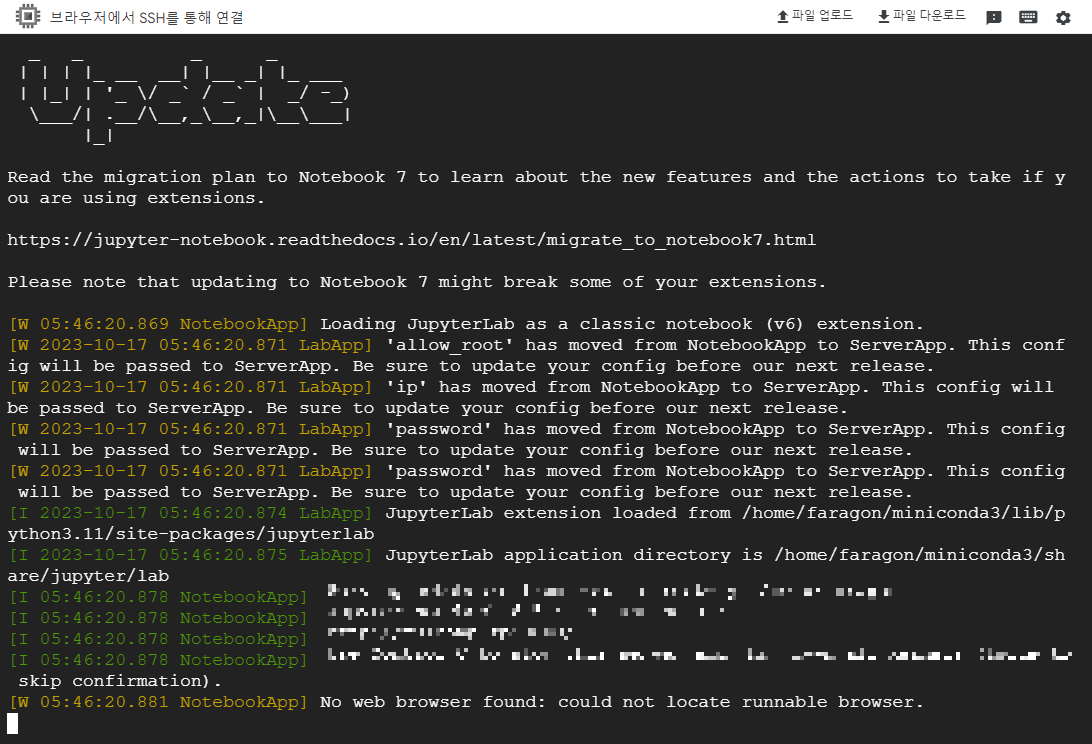
18. ip, 포트, 토큰 값을 확인하고 브라우저에 아이피, 포트를 입력한다.
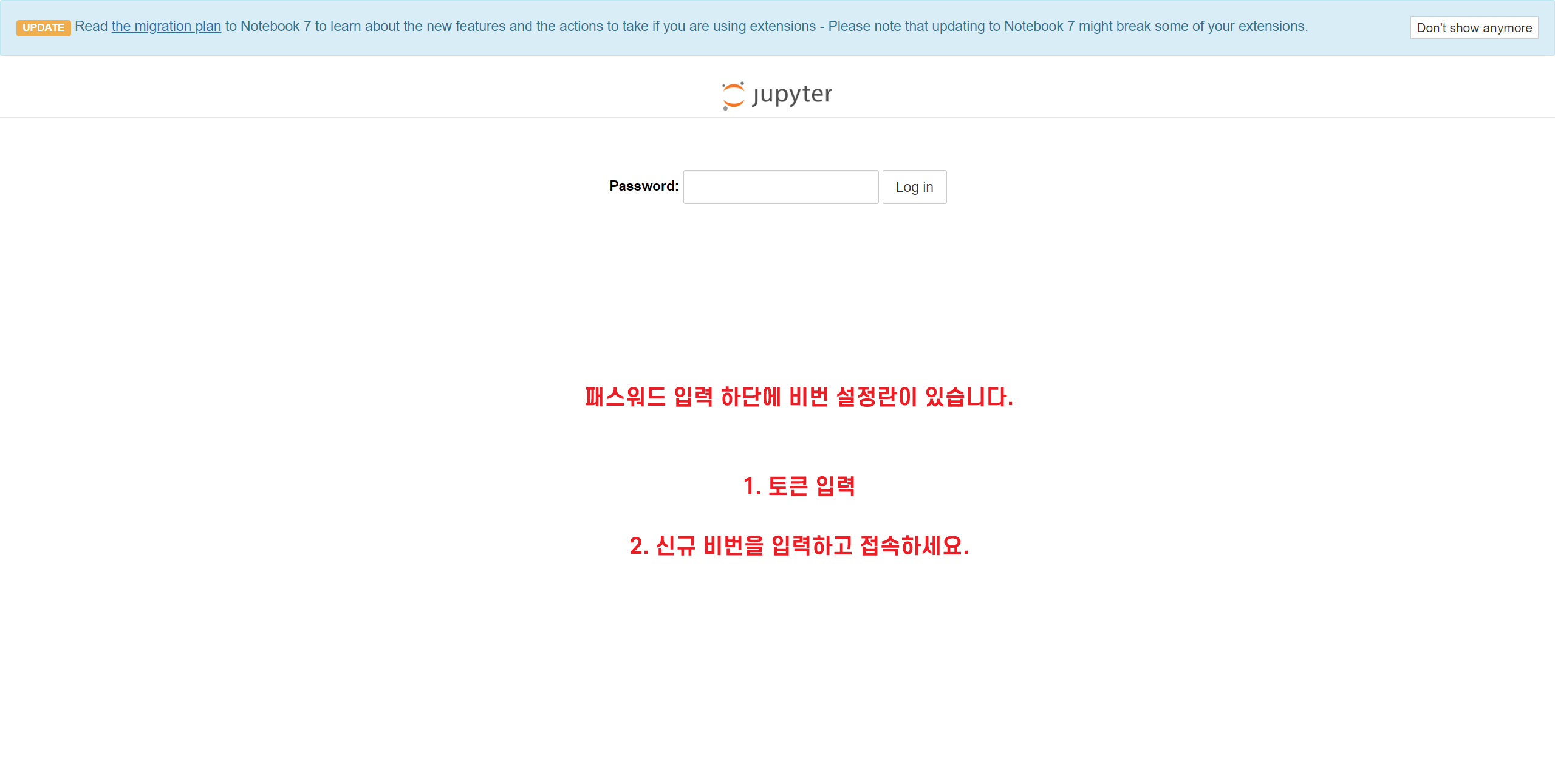
19. 비밀번호 설정란에 토큰과 비밀번호를 입력하고 접속하면 된다.
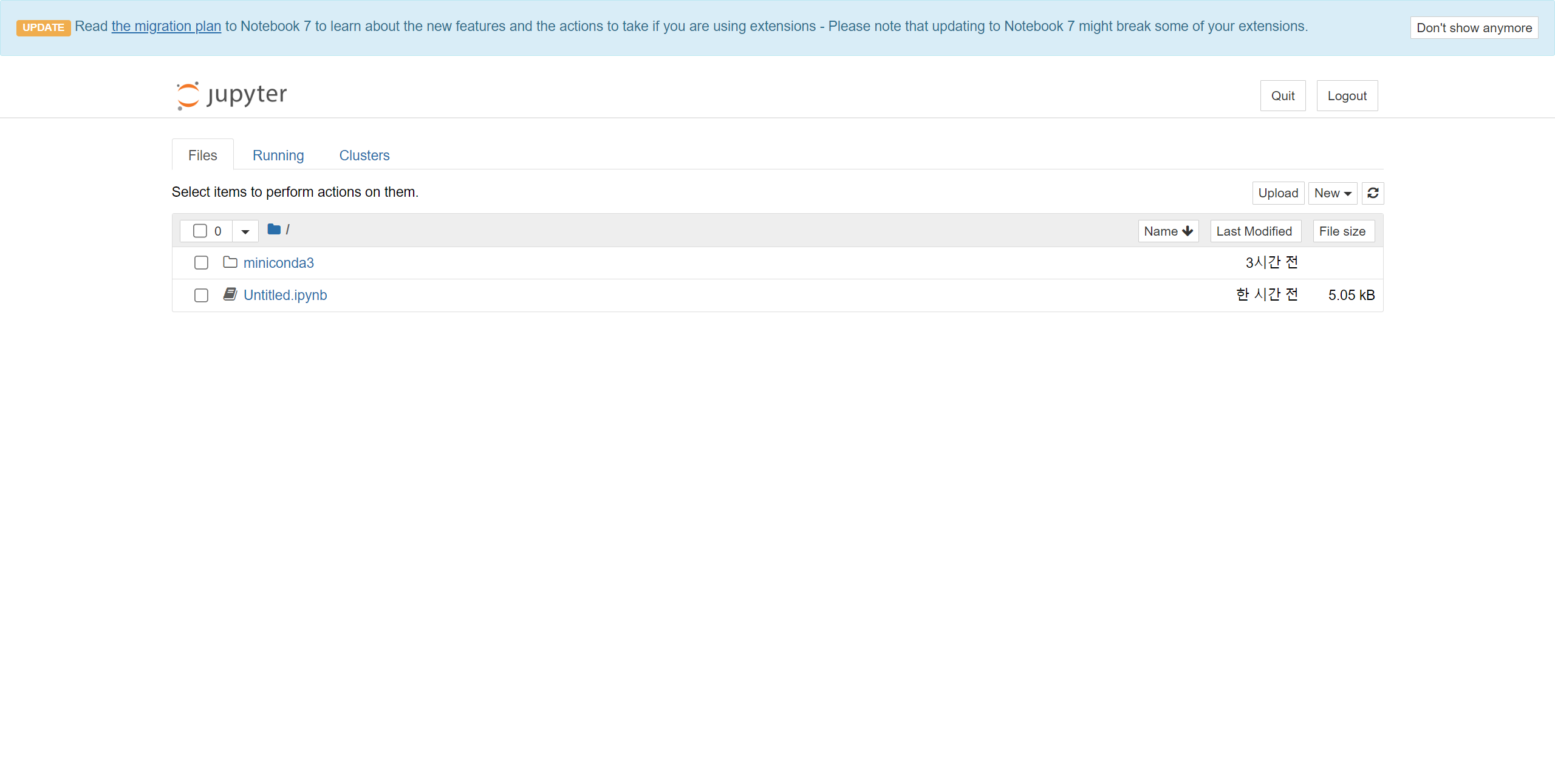
20. 접속화면에서 New를 통해 새로운 ipynb 파일을 만들어준다.
21. 새로운 ipynb에 아래의 코드를 입력해서 spark 사이트에 접속 되는지 확인해보자
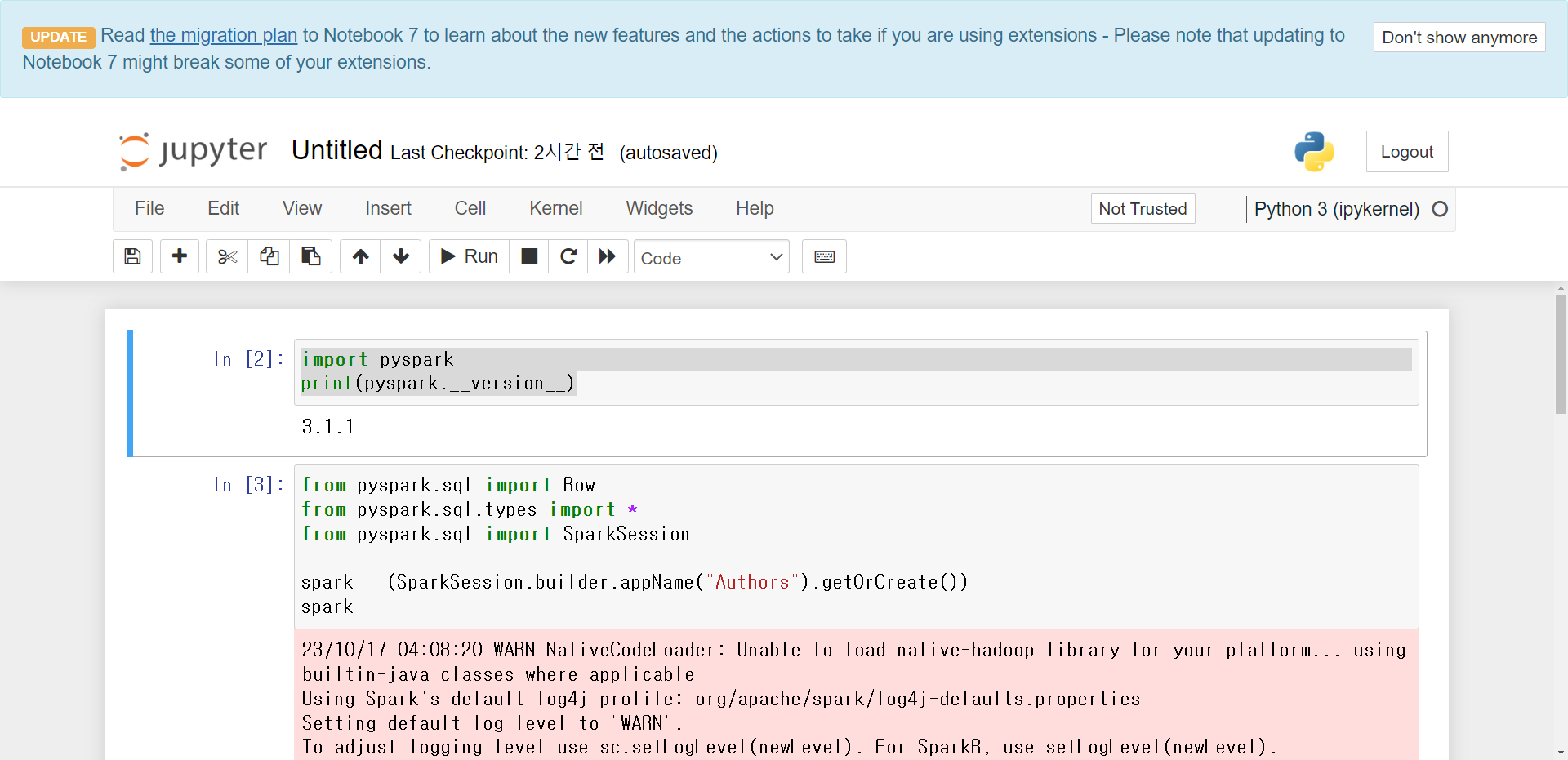
import pyspark
print(pyspark.__version__)
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
spark = (SparkSession.builder.appName("Authors").getOrCreate())
sparkhttp://[외부 아이피]:4040/ 를 입력하면 접속된다.

22.아래 처럼 접속되면 완료.

'SQL' 카테고리의 다른 글
| Spark SQL_ch 03_구글 GCP_Compute Engine에 깃허브 연동하기 (0) | 2023.10.18 |
|---|---|
| Spark SQL_ch 01_ Vs code에서 가상환경 연결하기 (0) | 2023.10.16 |
| Spark SQL_ch 00_ AWS 웹 서버 접속 방법 정리 및 Putty 세팅 방법 (0) | 2023.10.16 |
| PostgreSQL Ch 04. 실습 예제 (0) | 2023.10.13 |
| PostgreSQL Ch 03. 코드(쿼리) 문법#1 (0) | 2023.10.13 |




