MySQL_Ch. 05_상품 리뷰 데이터를 이용한 리포트 작성
231006_멀티캠퍼스 28회차 수강내용 中
실무 데이터를 통해 데이터 분석 마스터하기
SQL로 맛보는 데이터 전처리 분석 교재를 통하여 배운 내용 정리 ( p. 125 ~ p. 151 )
구매 링크 : https://www.yes24.com/Product/Goods/86544423
SQL로 맛보는 데이터 전처리 분석 - 예스24
SQL을 이용하여 현업에서 자주 사용되는 KPI 지표를 직접 추출해본다데이터 분석을 하기 위해서는 데이터베이스에 존재하는 데이터를 직접 추출할 수 있어야 한다. SQL은 우리가 데이터베이스에
www.yes24.com
◈ 오늘 배운 MySQL 문법 정리
▣ AVG(컬럼명) : 평균 평점 함수
-- Division Name 평균 평점
SELECT
`Division Name`
, AVG(RATING) AVG_RATE
FROM dataset2
GROUP BY 1
ORDER BY 2 DESC;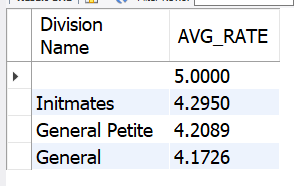
-- b) Department별 평균 평점
SELECT
`Department Name`
, AVG(RATING) AVG_RATE
FROM dataset2
GROUP BY 1
ORDER BY 2 DESC;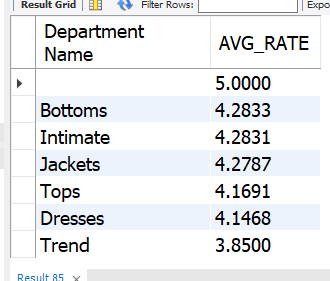
▣ 구간 그룹 집계 방법 CASE WHEN 또는 FLOOR() 함수
-- CASE WHEN
SELECT
CASE
WHEN AGE BETWEEN 0 AND 9 THEN '0009'
WHEN AGE BETWEEN 10 AND 19 THEN '1019'
WHEN AGE BETWEEN 20 AND 29 THEN '2029'
WHEN AGE BETWEEN 30 AND 39 THEN '3039'
WHEN AGE BETWEEN 40 AND 49 THEN '4049'
WHEN AGE BETWEEN 50 AND 59 THEN '5059'
WHEN AGE BETWEEN 60 AND 69 THEN '6069'
WHEN AGE BETWEEN 70 AND 79 THEN '7079'
WHEN AGE BETWEEN 80 AND 89 THEN '8089'
ELSE 'OVER 90'
END AS Age_Group
, AGE
FROM dataset2
WHERE `Department Name` = 'trend'
AND rating <= 3
;
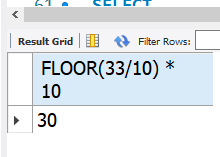
-- FLOOR 메서드 사용
SELECT FLOOR(33/10) * 10;
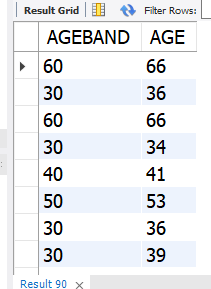
SELECT
FLOOR(AGE/10) * 10 AS AGEBAND
, AGE
FROM dataset2
WHERE `Department Name` = 'trend'
AND rating <= 3
;
▣ 50대 3점 이하 Trend 리뷰 살펴보기 ( BETWEEN 50 AND 59 )
-- 50대 3점 이하 Trend 리뷰를 살펴보기
SELECT *
FROM dataset2
WHERE `Department Name` = 'trend'
AND RATING <= 3
AND AGE BETWEEN 50 AND 59
LIMIT 10
;
▣ 컴플레인 내용 분석을 위해 부서 및 아이디 별 평균 평점 계산 및 랭킹화
-- P. 134
-- 리뷰 주 내용이 사이즈가 작은 것에 대한 컴플레인
-- Department Name, Clothing id별 평균 평점 계산
SELECT
`department Name`
, `clothing id`
, AVG(rating) AS AVG_RATE
FROM dataset2
GROUP BY 1, 2
;
-- 각 제품의 평균 평점(`AVG_RATE`)을 계산합니다.
-- Department(부서)내에서 AVG_RATE(평균 평점)을 기준으로 순위를 매긴다.
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY `Department Name` ORDER BY AVG_RATE DESC) AS 'Rank'
FROM (
SELECT
`Department Name`
, `clothing id`
, AVG(rating) AS AVG_RATE
FROM dataset2
GROUP BY 1, 2
) AS BASE;
▣ 평균 평점이 낮은 데이터를 추출 >>> 1위 ~ 10위 데이터 조회
CREATE TEMPORARY TABLE stat AS -- 임시 테이블 생성
-- 1위 ~ 10위 데이터 조회
-- 평균 평점이 낮은 데이터를 추출 하기 위해서 (상위 10개)
SELECT *
FROM (
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY `Department Name` ORDER BY AVG_RATE DESC) AS 'Rank'
FROM (
SELECT
`Department Name`
, `clothing id`
, AVG(rating) AS AVG_RATE
FROM dataset2
GROUP BY 1, 2
) A
) A
WHERE `Rank` <= 10
;
-- clothing ID만 추출한 뒤, 각 부서별 리뷰 텍스트를 추출
-- 임시 테이블 생성
CREATE TEMPORARY TABLE stat AS
SELECT *
FROM (
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY `Department Name` ORDER BY AVG_RATE DESC) AS 'Rank'
FROM (
SELECT
`Department Name`
, `clothing id`
, AVG(rating) AS AVG_RATE
FROM dataset2
GROUP BY 1, 2
) A
) A
WHERE `Rank` <= 10
;
SELECT * FROM stat;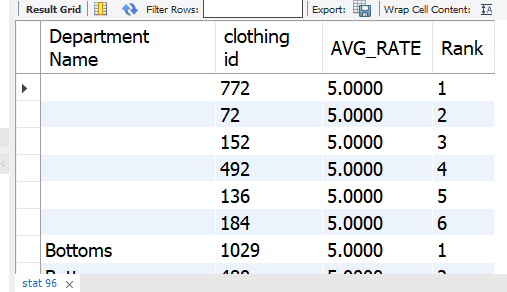
▣ WHERE, AND, IN 조건문
▣ WHERE, AND, IN 조건문을 통해 고객 번호와 리뷰 텍스트를 가져온다.
-- Clothing ID와 Review Text 컬럼을 선택합니다.
SELECT
`Clothing ID`
, `Review Text`
FROM dataset2
-- Department Name이 'Bottoms'인 행을 필터링하고,
-- Clothing ID가 18, 588, 1039, 1058 중 하나인 행을 선택합니다.
WHERE `Department Name` = 'Bottoms'
AND `Clothing ID` IN (18, 588, 1039, 1058)
ORDER BY 1
;
▣ 연령대별 낮은 점수를 받은 부서(Department Name)을 구하기
-- P. 139
-- 연령대별 Worst department
-- 각 연령대별로 가장 낮은 점수를 준 Department를 구하고,
-- 해당 Department의 할인 쿠폰을 발송한다.
-- 마케팅
-- 1. 연령대 별로 가장 낮은 점수를 준 department를 구한다.
-- 2. 연령대 별로 가장 낮은 점수를 준 department에 혜택을 준다.
SELECT
`Department Name`
, FLOOR(AGE/10)*10 AGEBAND
, AVG(Rating) AVG_Rating
FROM dataset2
GROUP BY 1, 2
;
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY AGEBAND ORDER BY AVG_Rating) AS RNK
FROM (
SELECT
`Department Name`
, FLOOR(AGE/10)*10 AGEBAND
, AVG(Rating) AVG_Rating
FROM dataset2
GROUP BY 1, 2
) A
;
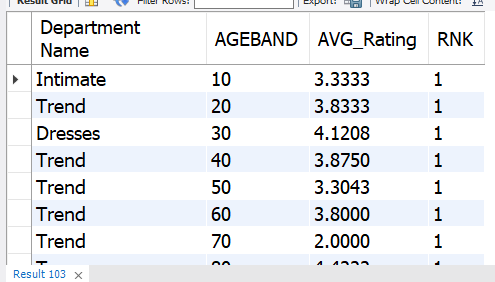
▣ 연령대별 가장 낮은 점수를 받은 부서(Department Name)을 순위 구하기
SELECT *
FROM (
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY AGEBAND ORDER BY AVG_Rating) AS RNK
FROM (
SELECT
`Department Name`
, FLOOR(AGE/10)*10 AGEBAND
, AVG(Rating) AVG_Rating
FROM dataset2
GROUP BY 1, 2
) A
) A
WHERE RNK = 1
;
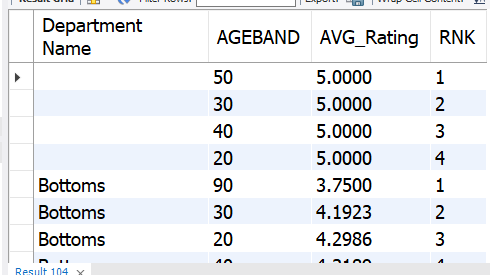
▣ 연령대별 가장 낮은 점수를 받은 부서(Department Name)을 순위 구하기
SELECT
*
, ROW_NUMBER() OVER(PARTITION BY `Department Name` ORDER BY AVG_Rating) AS RNK
FROM (
SELECT
`Department Name`
, FLOOR(AGE/10)*10 AS AGEBAND
, AVG(Rating) AS AVG_Rating
FROM dataset2
GROUP BY 1, 2
) A
;
▣ Q. MySQL Workbench 에서 ``와 '', ""가 주로 어떻게 쓰이는지 알려줘
From Chat GPT 작은 따옴표 ('), 큰 따옴표 ("), 그리고 역따옴표 (`)의
각각의 역할과 사용 예를 설명해드리겠습니다
- 작은 따옴표 ('):
- 용도: 작은 따옴표는 SQL 쿼리나 문자열 리터럴에서 문자열 값을 나타내기 위해 사용됩니다. 대부분의 SQL 데이터베이스에서는 문자열 리터럴을 작은 따옴표로 감싸야 합니다.
- 예시: SQL에서 문자열 비교나 필터링을 할 때 사용됩니다.
- SELECT * FROM customers WHERE last_name = 'Smith';
- 큰 따옴표 ("):
- 용도: 큰 따옴표도 문자열 리터럴로 사용할 수 있으며, 주로 테이블 이름, 열 이름, 또는 특수 문자 포함된 문자열을 나타내는 데 사용됩니다. 일반적으로 ANSI SQL 표준을 따르는 데이터베이스에서 사용됩니다.
- 예시: 테이블 이름 또는 열 이름에 공백이나 특수 문자가 포함된 경우에 사용됩니다.
- SELECT * FROM "Employee Information" WHERE "First Name" = 'John';
- 역따옴표 (`):
- 용도: 역따옴표는 주로 데이터베이스 시스템에서 테이블 이름, 열 이름, 데이터베이스 이름 등을 지정할 때 사용됩니다. MySQL과 같은 데이터베이스 시스템에서 자주 사용됩니다.
- 예시: 역따옴표를 사용하여 데이터베이스, 테이블, 열 이름을 나타냅니다.
- SELECT * FROM `employees` WHERE `first_name` = 'John';
각 따옴표의 사용은 데이터베이스 시스템과 SQL 구문의 표준 및 설정에 따라 다를 수 있습니다. 보통 SQL 표준을 준수하려면 작은 따옴표를 문자열 리터럴로 사용하고, 열 이름 등의 식별자에는 큰 따옴표 또는 역따옴표를 사용합니다. 따라서 실제 사용할 데이터베이스 시스템과 해당 시스템의 문법을 확인하고 적절한 따옴표를 선택하는 것이 중요합니다.
▣ 리뷰 텍스트에서 SIZE 단어 분류하기
USE mydata;
SELECT
`REVIEW TEXT`
, CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END AS SIZE_YN
FROM dataset2
;
▣ SIZE 텍스트 관련 컴프레인 횟수 및 비율 구하기
-- SIZE가 있는 REVIEW TEXT 합계
SELECT
A.*
, ROUND(N_SIZE / N_TOTAL, 2) AS RATE
FROM(
SELECT
SUM( CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) AS N_SIZE
, COUNT(*) AS N_TOTAL
FROM dataset2
) A
;
N_SIZE = SIZE 관련 클레임 리뷰수
N_TOTAL = 리뷰 총 개수
RATE = 클레임 리뷰수 / 총 리뷰수 = 비율 구하기
▣ CASE WHEN 을 활용하여 클레임 종류별 개수 파악하기
-- P. 145 그림 5-19
SELECT
SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) AS N_SIZE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) AS N_LARGE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) AS N_LOOSE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) AS N_SMALL
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) AS N_TIGHT
, SUM(1) AS N_TOTAL
FROM dataset2
;
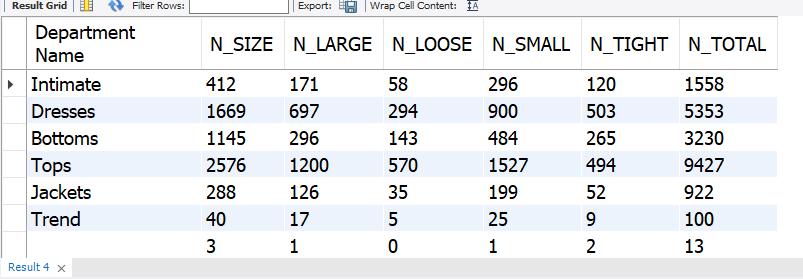
▣ Department Name(부서명)을 기준으로
GROUP BY 하여 각 부서별 각클레임의 개수를 파악하기
-- P. 146 그림 5-20
SELECT
`Department Name`
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) AS N_SIZE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) AS N_LARGE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) AS N_LOOSE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) AS N_SMALL
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) AS N_TIGHT
, SUM(1) AS N_TOTAL
FROM dataset2
GROUP BY 1
;
▣ AGEBAND, Department Name(부서명)을 기준으로
GROUP BY 하여 각 부서별 각클레임의 개수를 파악 및 특정 조건을 기준으로 필터링
-- P. 146 그림 5-21
SELECT
FLOOR(age/10)*10 AGEBAND
, `Department Name`
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) AS N_SIZE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) AS N_LARGE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) AS N_LOOSE
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) AS N_SMALL
, SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) AS N_TIGHT
, SUM(1) AS N_TOTAL
FROM dataset2
-- 서브쿼리를 주지 않으려면 파생변수 계산식 그대로 조건문으로 사용하면 됨
WHERE FLOOR(age/10)*10 = 20
GROUP BY 1, 2
ORDER BY 1, 2
;
▣ 옷 고유번호를 기준으로 리뷰 비율 구하기
각 옷 고유번호 별로 어떤 클레임이 많이 들어오는지 파악하고 개선사항을 제시할 수 있다.
-- 테이블 삭제 시 DROP TABLES SIZE_STAT_AS
CREATE TABLE SIZE_STAT_AS
SELECT
`clothing ID`
, ROUND(SUM(CASE WHEN `REVIEW TEXT` LIKE '%SIZE%' THEN 1 ELSE 0 END) / COUNT(*), 2) AS RATE_SIZE
, ROUND(SUM(CASE WHEN `REVIEW TEXT` LIKE '%LARGE%' THEN 1 ELSE 0 END) / COUNT(*), 2) AS RATE_LARGE
, ROUND(SUM(CASE WHEN `REVIEW TEXT` LIKE '%LOOSE%' THEN 1 ELSE 0 END) / COUNT(*), 2) AS RATE_LOOSE
, ROUND(SUM(CASE WHEN `REVIEW TEXT` LIKE '%SMALL%' THEN 1 ELSE 0 END) / COUNT(*), 2) AS RATE_SMALL
, ROUND(SUM(CASE WHEN `REVIEW TEXT` LIKE '%TIGHT%' THEN 1 ELSE 0 END) / COUNT(*), 2) AS RATE_TIGHT
, COUNT(*) AS N_TOTAL
FROM dataset2
WHERE `Department name` = 'bottoms'
GROUP BY 1
;
SELECT * FROM SIZE_STAT_AS;
금일은 마케팅 실무에 있어서 SQL이 어떤식으로 활용되는지 알아보는 시간을 가진 것 같다.
실무에서 SQL은 꼭 필요하다 느꼈고 더 깊이 배웠으면 좋겠다.
끝